Mastering Async
Understanding async design patterns and primitives
Who am I
- Conrad Ludgate (he/him) - https://conradludgate.com/
- I do Rust systems programming at Neon (Databricks), we host Postgres with extra features - https://neon.tech/
- I really like async Rust.
Where are the files?
https://github.com/conradludgate/async-design-patterns
Where are the docs?

https://async-patterns.conrad.cafe/
What will this workshop cover
Async Rust is still evolving as a paradigm, but many common design patterns have emerged as useful. Getting familiar with these patterns and tools will make it easier for you to develop async applications.
This workshop makes some assumptions, like that you will be using tokio and developing web-applications.
However, most of the ideas presented in this workshop will still map to other runtimes monoio, glommio, embassy,
and even map to other domains such as CLIs, desktop applications, databases, etc.
Chapter 1 - Actor Model
People often ask me what my favourite actor framework in Rust is. They are often surprised when I tell them tokio!
Quoting Wikipedia:
An actor is a computational entity that, in response to a message it receives, can concurrently:
- send a finite number of messages to other actors;
- create a finite number of new actors;
- designate the behavior to be used for the next message it receives.
There are many actor frameworks for rust:
Looking at kameo, we see
Defining an Actor
use kameo::Actor;
use kameo::message::{Context, Message};
// Implement the actor
#[derive(Actor)]
struct Counter {
count: i64,
}
// Define message
struct Inc { amount: i64 }
// Implement message handler
impl Message<Inc> for Counter {
type Reply = i64;
async fn handle(&mut self, msg: Inc, _ctx: Context<'_, Self, Self::Reply>) -> Self::Reply {
self.count += msg.amount;
self.count
}
}Spawning and Interacting with the Actor
// Spawn the actor and obtain its reference
let actor_ref = kameo::spawn(Counter { count: 0 });
// Send messages to the actor
let count = actor_ref.ask(Inc { amount: 42 }).await?;
assert_eq!(count, 42);Actors and Tokio
So, what does this have to do with tokio? Actor programming is a nice paradigm but as someone who is used to working with threads, tasks end up feeling more natural. However, it turns out that these paradigms are not so different.
We need a way to send messages to other actors. Fortunately, we have
an mpsc (Multi-produce; single-consumer) channel at our disposal.
mpsc is perfect for our needs as we want many actors to be able to send
messages, but only the one actor needs to receive them.
We need a way to spawn new actors. Fortunately, we have also a spawn method
also at our disposal.
Lastly, we just need a way to define the behaviour to take when a certain message is received.
For this we can use Rust enums and match to choose the behaviour.
An additional step we might want to consider is how actor replies work.
Either the request includes a request ID and mailbox and the reply can be sent as
a normal message, but from looking at existing frameworks, it seems more common to have a designated reply system.
Thankfully tokio also offers a oneshot channel, perfect for one-off messages (such a replies).
Why you might still want actors
Actors are not a way to implement concurrent high-scale applications. They are a way to structure applications.
Conveniently, this structure can scale to multi-node clusters where tokio cannot out of the box.
Ultimately with a multi-node setup you might be looking at a container orchaestrator like kubernetes to manage multiple processes on multple nodes, and then a message queue like kafka to manage sending messages to different nodes, where that node can then process the message using tokio. If you have a good actor framework, you might get this out of the box.
If you have a great actor framework, it might even be durable and allow synchronising state between nodes to allow actors to survive a node failure, although some state will inevitably be un-syncable (you cannot send a websocket connection to another node).
However, it is my opinion that the actor model is one you can still follow without needing to use an actor framework. We will take a look at this in the next chapter.
Chapter 2 - Actors between the lines
As I said in the last chapter, you can think of most tokio tasks as being an actor. I'm not super opinionated on "communicate via shared-memory" or "share memory via communication" camp. I say share memory if it makes your program more efficient. However, if you think about it, all tasks own some state, which is mutated when it receives some order of external influences.
A common manifestation of this are web frameworks like the modern day actix-web and axum. To prove my earlier point, actix-web,
despite the name, is no longer based on the actix actor framework, and is now built solely on top of tokio tasks.
When you use these web frameworks, what happens underneath is that:
- A tokio task is waiting on
TcpListener::accept - When a socket connects, it is spawned into a new tokio task
- The new tokio task waits to read data from that TcpStream until a HTTP Request is available
- The handler for the HTTP request is spawned into a new tokio task
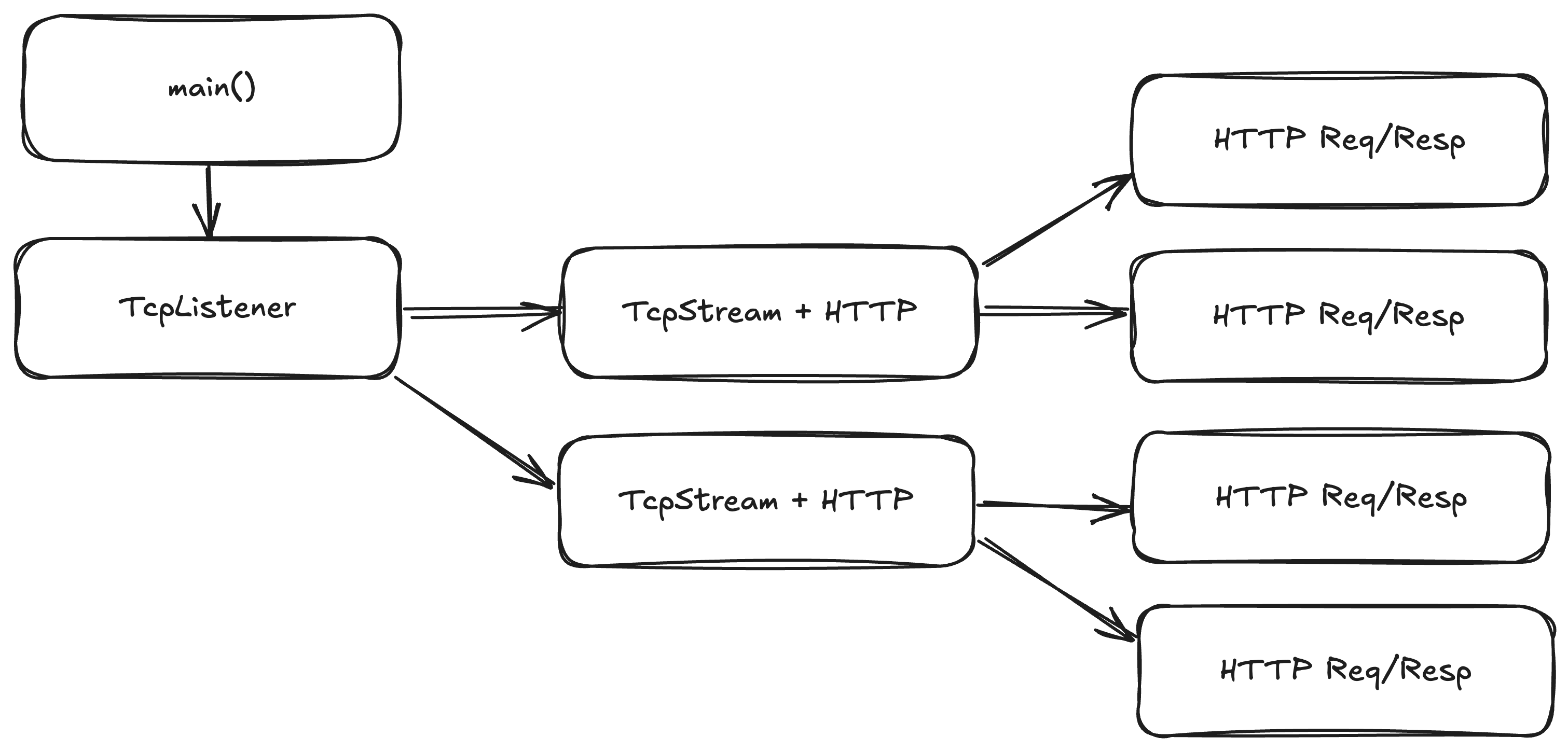
So let's look at the heirachy here:
- We have a task that owns a TcpListener.
- Which spawns many tasks that each own a TcpStream
- Which spawns many tasks that each own a HTTP Request
- Which spawns many tasks that each own a TcpStream
Chapter 3 - Cancellation
Getting an application running is relatively easy, as we have just seen.
Telling the application to stop running is also easy, via the interrupt/terminate signal offered by your operating system.
However, telling the application to stop running gracefully requires some effort.
What is Graceful Shutdown
We need to put our application into a limbo state, where it still waits for lower tasks to complete, but it will not create any new tasks. In the context of HTTP, that could be distilled into
- Stop accepting new TCP connections
- Tell all existing TCP connections to stop accepting new HTTP requests
- Wait for all HTTP requests to complete
- Wait for all TCP connections to close
Handling ctrl C in tokio
Tokio makes it easy to capture a ctrl-C even (commonly used for shutdown signalling)
#![allow(unused)] fn main() { tokio::signal::ctrl_c().await.expect("could not register signal handler") }
select!
Unfortunately, awaiting for a ctrl-C like we do above will not be super useful. We still need a way to do something about it.
This is where we will introduce select!, the ability to run two or more tasks, see which one finishes first,
and then stop the remaining tasks. It's available in many differnt forms
Which mode you use doesn't really matter, the outcome is practically the same.
#![allow(unused)] fn main() { loop { select! { _ = ctrl_c() => break, res = listener.accept() => { let (stream, _addr) = res?; tokio::spawn(conn_handler(stream)); } } } }
- If
ctrl_c()completes first,listener.accept()is "cancelled", and the loop breaks. - If
listener.accept()completes first, thenctrl_c()is "cancelled", and the handler is spawned and the loop repeats
Cancellation Tokens
In our applications, we will have to initate shutdowns in many places. Putting a ctrl_c handler everywhere can get
quite unweildy in practice, and it is also hard to test. To combat that, the tokio developers have provided
a feature called a CancellationToken
in their tokio-util crate.
Cancellation tokens can be cloned and passed around to all levels of your application. As soon as one of the tokens is cancelled, all the other tokens will detect this. They also have the ability to branch as children. Cancelling a parent will cancel all children, but cancelling a child will only cancel that child.
Using a cancellation token together with ctrl_c is pretty straightforward:
#![allow(unused)] fn main() { let token = CancellationToken::new(); tokio::spawn({ let token = token.clone(); async move { // cancels the token when the guard is dropped let _guard = token.drop_guard(); // wait until ctrl_c is received _ = ctrl_c().await.unwrap(); // drop the token guard... } }); // use the token loop { select! { _ = token.cancelled() => break, res = listener.accept() => { let (stream, _addr) = res?; // it might be sensible to also forward // a child cancellation token to the connection tokio::spawn(conn_handler(stream, token.child_token())); } } } }
There's a slightly cleaner implementation of the accept loop we can use now, thanks to a helper method by CancellationToken.
#![allow(unused)] fn main() { while let Some(res) = token.run_until_cancelled(listener.accept()).await { let (stream, _addr) = res?; tokio::spawn(conn_handler(stream, token.child_token())); } }
Waiting for completion
So far, we haven't actually achieved our goals of shutting down gracefully. We've only changed how shutdowns are triggered.
To wait for shutdowns, we can use another feature from tokio_util, TaskTracker.
If you're familiar with Go, this is similar to a WaitGroup.
We will replace each tokio::spawn with a task_tracker.spawn. TaskTracker then offers a .wait().await method
to wait until all tasks finish.
#![allow(unused)] fn main() { let tracker = TaskTracker::new(); while let Some(res) = token.run_until_cancelled(listener.accept()).await { let (stream, _addr) = res?; // spawn and track the task tracker.spawn(conn_handler(stream, token.child_token())); } // no more tasks will be spawned. tracker.close(); // wait for all tracked tasks to complete tracker.wait().await }
Signals
When running applications in a managed environment like docker or kubernetes, a shutdown request
might be received as a SIGTERM. This isn't cross-platform, so we're not using it here today,
but keep in mind that in a real webserver you might want to use
#![allow(unused)] fn main() { use tokio::signal::unix::{signal, SignalKind}; let mut sigterm = signal(SignalKind::terminate()) .expect("signal handler should be registered"); sigterm.recv() .await .expect("signal handler should not be disconnected"); }
Windows also has an alternative to SIGTERM, tokio::signal::windows::ctrl_shutdown()
Cancellation safety
I put "cancelled" in scare-quotes here, as it's quite a subtle problem.

Take a look at this example
#![allow(unused)] fn main() { let mut interval = interval(Duration::from_secs(1)); loop { select! { _ = foo() => println!("foo done"), _ = interval.tick() => println!("tick"), } } }
When the interval timer ticks forward, it
- stops processing the
foo()function. - print's "tick".
- the loop resumes and starts a new
foo()function.
Unless special care was put into making this foo() function, there's no guarantee that it will pick
up where it left off.
This at best is just a performance loss as you re-play all steps needed to get back to the same place.
At worst this will cause values to be lost forever, eg if foo() had read a message from a channel
but hadn't yet processed it.
#![allow(unused)] fn main() { async fn foo() { let value = some_channel.recv().await; // stopped here // value is lost forever process(value).await; } }
Workaround
There is a workaround, but unfortunately it is rather ugly. You must pin the future upfront, which allows you to re-use and resume the same async function.
#![allow(unused)] fn main() { let mut interval = interval(Duration::from_secs(1)); // store the foo state outside of the loop let mut foo_fn = pin!(foo()); loop { select! { // as_mut allows us to re-use the same foo state _ = foo_fn.as_mut() => { println!("foo done"); // restart foo_fn foo_fn.set(foo()); } _ = interval.tick() => println!("tick"), } } }
Cancellation Precautions
Sometimes APIs will assume cancel safety. This isn't always a bad thing, but it can cause unexpected bugs or missed optimisations.
An example I had at Neon: We operate a HTTP-based interface for postgres. We have a defensive implementation of a postgres connection pool that needs to make sure the connection is in a stable state before returning to the pool (no in-flight transactions).
If the client cancels a HTTP request, then we will want to rollback any transactions and check that the connection is steady, before retuning it to the pool. If we cannot complete these checks, we will discard the connection.
Most web frameworks in Rust will cancel handlers via drop if the HTTP request is cancelled, which can cause
us to discard a lot of postgres connections that would otherwise be easy to clean up. While there could
be many other ways to address this issue, the one we went with was utilising CancellationToken and drop guards.
#![allow(unused)] fn main() { let handler = service_fn(|req| async { let token = CancellationToken::new(); // gracefully cancel the handler on drop guard = token.clone().drop_guard(); // try and wait for the task to complete // spawned to allow it to continue making progress // in the background tokio::spawn(req_handler(req, token)).await; // if the task completed, there's nothing to cancel guard.disarm(); }); }
Graceful shutdown in hyper
Since we are using hyper for this project, I should point out that hyper has some graceful shutdown support out of the box. Since we want to partially stop the HTTP connection, but keep processing in-flight requests, we will be forced to use it.
On the Connection type, there is a method conveniently called graceful_shutdown which we will need
to call. Calling that will stop accepting new requests but continue processing old requests.
We will need to continue awaiting the connection object.
Since this connection future isn't necessarily cancel safe, this requires us to work with Pin, as we saw before.
Chapter 4 - Concurrency
Spawning multiple unrelated tasks is one thing, but sometimes you want to process multiple related but independant tasks concurrently to reduce latencies. Fork-Join, Map-Reduce, whatever you call it, how would be best represent this in async Rust?
It's important to establish what we want to process concurrently, and what even we mean by concurrent.
Concurrency vs Parallelism
If you needed to transcode 8 different video streams because you're building a competitor to youtube, then async rust won't really help you. Instead, you'd prefer something like rayon, since you need pure parallelism.
Async Rust really shines when you mostly need to wait, and when most of the time is spent waiting, you can use that time waiting to queue up other tasks. This is where the concurrency shines. In our case, we might use that to issue 10 HTTP requests at the same time, as most of that time is spent waiting.
Channel
One approach we might introduce is to use mutli-produce single-consumer channels, and spawn a tokio task per item we want to dispatch.
Channels are self-closing, which allows us to easily detect when all tasks are complete, so we don't need anything else like a TaskTracker.
#![allow(unused)] fn main() { let (tx, mut rx) = tokio::sync::mpsc::channel(1); for item in items { let tx = tx.clone(); tokio::spawn(async move { tx.send(handle(item).await) }); } drop(tx); let mut responses = vec![]; while let Some(resp) = rx.recv().await { responses.push(resp); } }
JoinSet
This is again so common that tokio provides a dedicated utility for this, JoinSet
#![allow(unused)] fn main() { let mut joinset = JoinSet::new(); for item in items { joinset.spawn(async move { handle(item).await }); } let mut responses = vec![]; while let Some(resp) = joinset.join_next().await.unwrap() { responses.push(resp); } }
FuturesUnordered
There's one issue with using spawn for concurrency that can sometimes be an issue, 'static.
All the tasks might need to share some state that is owned by the parent task.
There's currently no sound way (ask me later/tomorrow) to spawn a tokio task such that
it can borrow from it's parent. Fortunately, you don't need to spawn a task to use concurrency.
We saw earlier how select! can run tasks concurrently, and that works without spawn. Unfortunately,
that doesn't scale for dynamic tasks, so we will need something else but something similar.
From the futures crate, you can find futures::FuturesUnordered. It works very similarly to the JoinSet
#![allow(unused)] fn main() { let mut futures = FuturesUnordered::new(); for item in items { futures.push(async move { handle(item).await }); } let mut responses = vec![]; while let Some(resp) = futures.next().await { responses.push(resp); } }
The futures crate has some extra goodies that makes this pattern simpler, since it is again so common:
#![allow(unused)] fn main() { futures::stream::iter(items) .map(|item| async move { handle(item).await }) .buffer_unordered(10) .collect::<Vec<_>>() .await }
There's a risk here, however. https://rust-lang.github.io/wg-async/vision/submitted_stories/status_quo/barbara_battles_buffered_streams.html
Chapter 5 - Working with Bytes
When dealing with the network, it can often be desired to stream responses so the client can start processing them faster, as well as reducing the amount of active memory is needed for an inflight request.
When it comes to stream processing, it usually means byte processing. However, applications usually don't want to work with bytes, but with "messages" instead.
For example, this could be rows from a database, translated into JSON.
- The database will stream bytes to the server
- The server will interpret those bytes as rows
- The server will convert the row into JSON
- The server will send the JSON as bytes to the client.
Being comfortable with handling bytes will thus be very important in many applications.
Project
Stream in a response of JSON Lines, translate the JSON into some other format, restream the output as JSON Lines.
Buffers
When working with bytes, what we really mean is working with byte buffers. Your first
thought for a buffer to use would be a Vec<u8>. This is a good first choice in many applications,
but doesn't work well in network applications. When sending data, you might consume the first half of the data,
which requires re-copying all the bytes around the buffer. Instead, a VecDeque<u8> ring buffer tends to be more appropriate.
However, if you consider the example of HTTP, where we have a task per request, all sharing the same TCP stream in a separate task. When streaming bytes out of your HTTP request, you will have to share those bytes to some other task. This ends requiring you shuffle allocations between tasks constantly which ends up being very awkward, since we unfortunately do not have a garbage collector to help us when sharing memory between tasks. To deal with this, there's a convenient crate that tries to put reference counters (like Arc) in the right places so you can mostly ignore this.
Unsurprisingly, this crate is called bytes. It is well integrated with tokio.
Arc ptrs ┌─────────┐
________________________ / │ Bytes 2 │
/ └─────────┘
/ ┌───────────┐ | |
|_________/ │ Bytes 1 │ | |
| └───────────┘ | |
| | | ___/ data | tail
| data | tail |/ |
v v v v
┌─────┬─────┬───────────┬───────────────┬─────┐
│ Arc │ │ │ │ │
└─────┴─────┴───────────┴───────────────┴─────┘
There's only 2 types in this crate. Bytes and BytesMut. As the names imply, one is read-only, the other is read-write.
Importantly, you can split a BytesMut into two, sharing the same buffer - and then you can freely convert
those BytesMuts into Bytes. And of course, these are Send so are safe to share between tasks.
AsyncRead
One advantage of tokio::io over std::io is the ability to read into un-initialised memory.
This can be a nice optimisation as you don't need to run an "expensive" routine to write 0s into
the 1MB buffer (only 5us on my hardware, but still!).
To utilise this, we can use the read_buf method.
#![allow(unused)] fn main() { // with read, you have to pre-initialise the bytes let mut buffer = vec![0; 1024*1024]; // read into our buffer let n = stream.read(&mut buffer).await?; // actually available data let data = &buffer[..n]; }
#![allow(unused)] fn main() { // with read_buf, you don't even need to pre-allocate, but we can if we think it will improve efficiency. let mut buffer = Vec::with_capacity(1024*1024); // the buffer will be resized as data is read, and it is always read to the end of the buffer. // no accidental over-writes! stream.read_buf(&mut buffer).await?; // all initialised data in the vec is available to read. no need to track the length. let data = &buffer; }
AsyncWrite
AsyncWrite also has better buffer support.
In std::io::Write, you have write() and write_all(). These two are technically enough to do anything, but it could be annoying.
Let's say you want to wait until a request header is written, but then you are happy to let the remainder of the body be written
asynchronously. You have the header and some of the body written into a Vec<u8>. Using write_all here would be wrong,
since you will end up waiting until the entire buffer is sent, not just when the header is sent. So we need to use write to get
what we want.
#![allow(unused)] fn main() { // assuming these exist let mut buf: Vec<u8>; let mut stream: TcpStream; let mut header_length: usize = HEADER_LEN; let mut written: usize = 0; while written < header_length { let n = stream.write(&buf[written..])?; written += n; } // remove it from our buffer. buf.drain(..written); }
Using a Vec here isn't ideal with the last step, as it needs to copy the bytes to the start of the vec. a Bytes would work better, so let's use that, along with tokio's write_buf.
#![allow(unused)] fn main() { // assuming these exist let mut buf: Bytes; let mut stream: TcpStream; let mut header_length: usize = HEADER_LEN; let mut written: usize = 0; while written < header_length { let n = stream.write_buf(&mut buf).await?; written += n; } // the written data was already removed from our buffer. }
While the changes are quite minor, it removes some places where subtle bugs can creep in.
It's really easy to forget to use &buf[written..] when chaining calls to write, I am guilty of writing code like this
and getting really broken data as a result.
Chunking
Not all bytes are the same. If you are working with TCP or QUIC, you get to work with byte "streams". Byte streams have no hard boundaries about the bytes you get. You could ask for 1 byte or you could ask for 10000 bytes.
Websockets or HTTP2, however, are "frame" based. You send and receive discrete chunks of bytes, and these could be used to define individual messages.
Because of these differences, there's often different APIs when working with them.
For instance, The tokio-tungstenite crate for websockets exposes a WebSocketStream which is a Stream<Item = Result<Message, Error>> + Sink<Message, Error = Error>. Sink is something we haven't looked at yet, but it effectively abstracts a channel sender, where Stream is like the channel receiver.
hyper and by extension axum use a custom http::Body trait in requests/responses. This is similar to a Stream<Item = Result<Frame<Buf>, Error>>, but is designed specifically with http in mind. There are helpers in the http-body-util crate
that allow freely converting between Body and Stream, though.
Each of these only offer a way to receive the entire message only, no partial messages. Body::next_frame() always returns
a single frame. WebSocketStream::next() only returns a single message.
However, tokio::net::TcpStream and quinn::RecvStream/quinn::SendStream all work over the tokio::io::AsyncRead/tokio::io::AsyncWrite trait, which allows partial reading and writing.
Excess Buffering
One problem that arises with these different abstractions is that layering them can cause excess buffering.
TCP is based on IP packets. IP packets are framed and have a maximum size depending on the maximum transmission unit (MTU) of your network. When you write to a TCP stream, the data is split into buckets for each IP packet to be sent. These are then buffered by your OS for re-delivery incase these IP packets get lost.
Let's say you use TLS on your connection. TLS sends data as frames, since each encrypted block of bytes needs some extra
metadata - like the authentication tag. Because of this, the TLS wrapper needs to buffer data from the TCP stream
until it can read a full TLS frame. tokio_rustls::TlsStream exposes this data back as a tokio::io::AsyncRead interface.
On top of this you might have a WebSocketStream. Since websocket messages are framed, if a large websocket message
is sent, then the websocket stream will need to buffer the data from the TLS stream until it has enough to
process the entire websocket message into one Vec<u8> to give you.
Problems this causes
This manifested as a problem at Neon for the service I work on. Postgres uses its own TCP/TLS based protocol, but we found that not all environments (edge/serverless) supports raw TCP. They did however support websockets. We decided to implement a simple middleware client that turns the postgres byte stream into websocket messages, then my service takes those websocket messages, and interprets them as bytes.
Postgres is itself a framed based protocol, so we had an extra layer of buffering. This caused a messurable amount of lag as messages would need to fill each buffer before being processed. Notably, if a client sent a large query in a single websocket message, then we would need to buffer the entire message until we could start then sending it to postgres.
I fixed this by forking and re-writing the websocket server implementation we were using. Fortunately, websockets has a concept of "partial messages", so in the server layer, I managed to modify it to split a large message into smaller chunks, which reduced the amount of buffering needed significantly.
An additional optimsation could be sharing the buffer needed with rustls's upcoming "unbuffered" API. This API
no longer has a buffer of its own, and asks the user to provide their own buffer. You could then use this same buffer as the one used for websocket processing.
Codec
As I've eluded to, the framed/chunked/message based APIs of Websockets or HTTP2, or even TLS for that matter, will end up being sent over a byte-stream write. Similarly, a byte-stream reader will end up being buffered then parsed into messages.
Because this is so common in many protocols (HTTP2, TLS, Postgres, MySQL, Websockets), I want to share a great utility
provided by tokio-util called codec.
Sending data
#![allow(unused)] fn main() { let mut stream = TcpStream::connect(...).await?; // create a new buffer let mut buf = BytesMut::new(); // receive some message from a stream while let Some(msg) = recv_msg().await { // encode the message into our buffer msg.encode_into(&mut buf); // split the buffer in two. // `msg_data` contains all data written from the previous encoding // `buf` will now be empty // this will not need to allocate let msg_data = buf.split(); // turn this buffer into a shared buffer let msg_data = msg_data.freeze(); // send the data chunk to the tcp stream. stream.write_all(msg_data).await; } }
Receiving data
#![allow(unused)] fn main() { let mut stream = TcpStream::connect(...).await?; // create a new buffer let mut buf = BytesMut::new(); loop { // read some data into our buffer if stream.read_buf(&mut buf).await? == 0 { break; } // try find where our next message separator is while let Some(end_of_msg) = peek_msg(&buf) { // split the buffer in two. // `msg_data` contains all the data for a single message // `buf` will be advanced forward to not contain that message // this will not need to allocate let msg_data = buf.split_to(end_of_msg); // turn this buffer into a shared buffer let msg_data = msg_data.freeze(); // parse the data and process let msg = parse_msg(msg_data)?; handle(msg).await; } } }
tokio_util::codec allows you to abstract the "encode"/"peek"/"parse" APIs into an Encoder and Decoder trait. They then provide the types FramedWrite and FramedRead as appropriate
to convert from your messages/chunks/frames into a byte stream, and vice versa.
Sending data
#![allow(unused)] fn main() { let stream = TcpStream::connect(...).await?; let mut writer = FramedWrite::new(stream, MyCodec); // receive some message from a stream while let Some(msg) = recv_msg().await { writer.send(msg).await?; } }
Receiving data
#![allow(unused)] fn main() { let stream = TcpStream::connect(...).await?; let mut reader = FramedRead::new(stream, MyCodec); // receive some message from a stream while let Some(msg) = reader.try_next().await? { handle(msg).await; } }
Of course, I've skipped over how MyCodec works, but it's a couple traits to implement
that defines the functions like encode_into and parse_msg that I didn't define above,
and it helps clean up the core logic into a cleaner abstraction.
Let's see what a codec might look like for JSONLines using serde and serde_json.
If you're not familiar, JSONLines is a very simple modification to json:
{"foo": "bar"}
{"foo": "baz"}
Each entry is on a separate line, and there are no new-lines in the individual json entry encoding.
Encoding
Encoding data is always easier than decoding, as you don't have to program so defensively. Here's how it might look.
#![allow(unused)] fn main() { struct JsonLinesCodec<S>(PhantomData<S>); impl<S: Serialize> Encoder<S> for JsonLinesCodec<S> { type Error = std::io::Error; fn encode(&mut self, item: S, dst: &mut BytesMut) -> Result<(), Self::Error> { // json encode the item into the buffer serde_json::to_writer(dst.writer(), &item)?; // add new-line separator dst.put_u8(b'\n'); Ok(()) } } }
Decoding
Although I suggested that decoding can be more challenging, it's still reasonably easy.
#![allow(unused)] fn main() { struct JsonLinesCodec<S>(PhantomData<S>); impl<S: DeserializeOwned> Decoder for JsonLinesCodec<S> { type Item = S; type Error = std::io::Error; fn decode(&mut self, src: &mut BytesMut) -> Result<Option<Self::Item>, Self::Error> { let Some(new_line) = src.iter().position(|&b| b == b'\n') else { // not enough data ready yet return Ok(None); }; // remove full line from the buffer let line_end = new_line + 1; let json_line = src.split_to(line_end).freeze(); // parse the json line. let item = serde_json::from_slice(&json_line)?; Ok(Some(item)) } } }
Push vs Pull
Not all byte APIs are the same. At the bare minimum, we might look at Read and Write for example.
Read is a 'pull' based API (important, I don't mean poll based API).
Write, meanwhile, is a 'push' based API.
When I want to read some data, I ask for some data. When I want to write some data, I send it to the writer. This might seem trivial, but it depends on you having an active task to push data.
Imagine instead you are sending the contents of a file in a HTTP response. Your HTTP request handler will need to read in some of the contents of the file, and then actively write it to the HTTP response. This is all assuming you even have access to the HTTP connection, which hyper/axum don't give you.
Instead, some writing APIs end up being pull based too. Instead of axum giving you an AsyncWrite
interface that you push to, you instead return a Response<Body>, where this Body is a pull-based
frame stream. You could implement this over a file to read a chunk of data from the file, then frame it and
return that.
Ultimately, hyper will then convert that data pulled from your response body into pushes to the underlying TCP stream, but the API presented is still pull based. hyper asks you for more data when it is able to send, rather than your task waiting to push data. This isn't always super trivial to work with, however.
Chapter 6 - Synchronising state between tasks
No task works alone - which we have already seen. Spawning tasks, sending messages, awaiting their results, all standard procedure. However, there's more tools in our toolbelt, and I think it would be good to play with them.
Locking
All the way at the beginning of this workshop, I brought up that I'm not a purist on "share memory to communicate" or "communicate to share memory". I would prefer to use whatever the right abstraction is for the task at hand. A well beaten drum is that channels are usually implemented via shared ring-buffers. The underlying implementation is not important, but the abstraction you present is.
So why am I about to tell you that async Mutex/RwLock's are evil and should never be used?

This seems to be a topic many people struggle with. So I think it's worth having a discussion about. A big topic in async, which I haven't properly mention yet, is blocking. Blocking is something that caused great trouble in async code as when a function "blocks", it stops the runtime from being able to use this thread for any other task. This is especially bad when this blocking is mostly just waiting (IO or waiting for a mutex), as the thread is doing literally nothing, while the runtime might have tasks it wants to schedule. So, if a mutex lock might have to wait, why would we not want an async version instead?
I believe this stems from a set of misunderstandings about mutexes in general.
How fast is a mutex
Mutexes are fast. Very fast. You can lock a mutex in 20ns, assuming it's not currently locked and no other threads are also trying to lock it. In my humble experience, that's extremely common.
Let's say you hold a lock for 50us (which is quite a lot of time in Rust - you can do a lot in 50us), and you have 10000 requests per second, each request only touches the lock once. If we expect the tasks to be evenly distributed over time, then the lock is expected to have only 1 task with access, and unlocked the other 50% of the time.
Since occasional spikes will happen, it's possible some tasks will need to queue up. Potentially the extra contention of the lock will cause the throughput to fall which causes more tasks to backup etc. Fortunately, since tokio only uses a few threads, the content ends up staying low. In my experience, switching to an async mutex does not reduce contention as the tokio mutex internally uses a blocking mutex! If these spikes reducing your throughput are a concern, my advice would be to reduce the average 50us lock duration, or try and shard your dataset to reduce the chance of a lock collision.
Mutex protects data
This might be a concept that only really applies to Rust. A mutex in some other language might be how you introduce any critical section, but in async Rust we have some other tools that are much likely better. I would strongly argue that a mutex is to protect data, whereas a semaphore should be used to introduce a critical section.
What do I mean by this? A critical section is a span of time where you want only a few things (possible one thing) to occur at a time. You should reason to yourself why you want a critical section, as they introduce a direct bottleneck to your throughput, but they are absolutely valid.
A mutex protects data and data only. It does this via a critical section, but it should not be used for a critical section.
Emulating an async mutex
You can easily emulate an async mutex via a semaphore and a blocking mutex. You can use the semaphore with permit count of 1 to define your long critical, and then for any data you need to modify, use the regular blocking mutex. It will be uncontended.
#![allow(unused)] fn main() { // only 1 permit let semaphore = Semaphore::new(1); let data = Mutex::new(1); let _permit = semaphore.acquire(1).await; *data.lock().unwrap() = 2; }
In fact, tokio's Mutex basically does this, although using an UnsafeCell rather than a mutex.
#![allow(unused)] fn main() { pub struct Mutex<T: ?Sized> { #[cfg(all(tokio_unstable, feature = "tracing"))] resource_span: tracing::Span, s: semaphore::Semaphore, c: UnsafeCell<T>, } }
Fair RwLocks
RwLocks are especially problematic. They often give a false sense of security. What's wrong with the following sentence?
Many tasks hold a read lock during the entire request, and occasionally one task very briefly holds a write lock
The problem is fairness.

When a write lock is queued, it forces all future read locks to also be queued. The write lock will queue until the final previous read lock is still acquired.
This is clearly not the intention with the quote above, so it's a bug waiting to happen. Assuming that the intent
is to have a cached configuration value, perhaps a watch channel might be a better fit. If you don't need to track updates, using the arc-swap crate might be a viable alternative.
Semaphores
I've spoken a bit about why we should use semaphores instead of mutex where possible. What's nice about semaphores is that they scale to multiple permits.
Setting limits in your application throughput is always sensible. Your application has limits, you just haven't documented them. Eventually you will have too much bandwidth, CPU, memory, or upstream API rate limits. It is good to measure it and make it official with a semaphore. If you do this, if you hit your limits, you will at least be able to reason about it and have the appropariate logging.
Speaking of limits, tokio's channel implementations use semaphores internally for this reason. You have probably seen that there's bounded and unbounded channels. Bounded channels can only buffer a fixed number of messages, which is good to prevent accepting messages if you know it will be stuck in a queue for ages, and taking up space in memory. Internally, they uses a semaphore where each message holds a permit.
Notify
The tokio docs suggest that you should use an async mutex to guard resources like a database connection. I still disagree with this, although it is reasonable if you cannot afford any kind of refactor. That said, I would still implore you to try and get a proper connection pool resource.
Writing your own connection pool is quite easy, if you need one. Simply, you might think of a pool
as a VecDeque<T>. You can pop_front from the pool to get access to a connection, and then use push_back to re-queue the connection. To have this between threads, you obviously need a Mutex to protect this vec. However, if there are no connections ready in the pool, how do you wait for one?
One less elegant way is to use a semaphore, Make sure the semaphore has the same number of permits as connections. Before you lock the mutex, acquire a permit for it. This works fine, and I would not mind if I saw this in production. That said, I think this is a great opportunity to show off one of my favourite synchronisation primitives in tokio.
If all you need is a notification, how about a primitive called Notify?
#![allow(unused)] fn main() { struct Pool<T> { conns: Mutex<VecDeque<T>>, notifications: Notify, } impl<T> Pool<T> { pub async fn acquire(&self) -> Conn<'_, T> { // register our interest self.notifications.notified().await; // a value is now ready let mut conns = self.pool.lock().unwrap(); let conn = conns.pop_front().expect("a conn should exist"); // more connections ready, store a notification if !conns.is_empty() { self.notifications.notify_one(); } Conn { pool: self, conn: Some(conn) } } pub fn insert_conn(&self, conn: T) { // insert the conn into the pool let mut conns = self.pool.lock().unwrap(); conns.push_back(conn); // notify the next task that a connection is now ready self.pool.notifications.notify_one(); } } struct Conn<'a, T> { pool: &'a Pool<T>, // option needed to return it to the pool on drop later // it will always be Some conn: Option<T>, } // return the conn on drop. impl<T> Drop for Conn<'_, T> { fn drop(&mut self) { let conn = self.conn.take().unwrap(); self.pool.insert_conn(conn); } } }